
1) What is a BI Application
1.1) Definition
BI Application or Prepackaged BI
Application can be defined as "An off the shelf available pre built BI Application
which can cater to an Organization Long term BI needs and should Integrate
seamlessly into the existing technical architecture". BI Application
should be able to cater to every audience inside the organization i.e. from the
strategic and the tactical level to the operational level and should seamlessly
integrate in the technical architecture to deliver consistent business value.
This application can be simply a
module implemented for a specific department for example Finance, Supply Chain
or Human resource. No one today will espouse the thought that one BI tool is
all one needs; However it is important to make sure that this module integrates
into the larger landscape and delivers Consistent value. In such a world, a BI
application may be merely a subject area of a much larger BI system that uses a
particular tool. Your information is integrated across your major data sources,
but the usage is tailored to a particular user community. This application
should be backed up by a leading vendor and should have a long term Roadmap
Consistent with the Organizational Long term plans.
This
application is a common of the shelf (COTS) product and at minimum should consist
of the following key components:
- An ETL Tool
- Centralized Console to Manage and Recover ETL
- Reporting platform, A reporting engine and a report Delivery mechanism
- Pre Built ETL Adaptors (Adaptors for Leading source systems)
- A Unified Data Model
- Pre Built Dashboards and Reporting contents
1.2 BI Applications Functions
The following section provides a
quick checklist for the major objectives and basic minimum functions which a
Pre-Built BI Application Should Support:
Objectives
Objective
|
Description
|
Faster Time to value
|
The BI Application suite should be able to provide quick
feedback or a taste of the solution in the making. In our experience
applications which provide some kind of flavor during the early phases of the
implementation cycles have the highest acceptance rates.
|
Increases ROI
|
The return on investment should be high; It only makes sense
to do any IT investment if the returns are at least 10 times during a5year
tenure. The first thing a CFO should be asking to any application provider is
the pro-rated ROI in 5 year tenure.
|
Seamlessly Integrates into existing architecture
|
The application should integrate
seamlessly into the existing architecture; this also means that there should
be minimum overheads of purchasing 3rd party suites and packages
to support the new application.
|
Flexibility to customize and
extend
|
The application should provide
API’s and other features which support immediate extension to the complete
suite.
|
Functions
Function
|
Description
|
Set up user security
& visibility rules
|
Role based access to user should
be supported out of box
|
Pre-Build ETL
programs for every data source
|
Pre Built ETL modules (adaptors)
for leading sources (ERP, CRM, SCM and other industry standard sources)
|
Support for Heterogeneous sources
|
In Built support for all the
existing and future sources of an organization. This should be built in at
the ETL as well as the reporting tier
|
Unified data model
|
Enterprise information should be available
in a unified data model
|
Supports Data Lineage
|
Data lineage should be available
out of the box
|
Supports Multi Currency
|
The application should have
built-in support for Multi-Currency storage and reporting
|
Supports Multiple Time zones
|
The application should have
built-in support for Multi-Time Zone reporting
|
Support for Conformed dimensions for drill across
|
Value Chain and Drill across
functional areas should be supported
|
Support for multiple and alternate hierarchies
|
Inbuilt support for multiple and
alternate hierarchies
|
Supports all kind of Fact tables
|
Transaction grain, Snapshot and
all kind of fact tables should be supported
|
Robust Reporting tool in the
background
|
The reporting tool should be a
part of vendor overall solution
|
Provides most of the common reports and Dashboards out of
the box
|
Standard and Most common reports
should be available out of box
|
Extensive support for pre built metrics
|
Extensive library of built in
metrics should be supported
|
3 Oracle BI Applications Architecture
Oracle BI Applications
Architecture
The Oracle BI platform includes a server and end user tools
such as dashboards, query and analysis, enterprise reporting, disconnected
access to the data -- all supported by a unified, model-centric server
architecture. On top of this platform, there is a set of analytic applications
consuming the operational data sources and delivering greater insight to larger
user communities across the organization via dashboards, query and analysis,
alerts, briefing books, and disconnected mode - the same tools we mentioned
under the BI platform. (Fig x- Oracle BI Applications Architecture),
shows the Oracle BI Applications Architecture.

3.2 Oracle Business Intelligence Applications Components
This Section lists out (Fig 5 Oracle BI Application Components) the various components available inside Oracle BI Applications and how do they interact, in the following section each of these components are described in further detail.
3.2.1 Datawarehouse Administration Console
Datawarehouse Administration Console (DAC) is “a centralized
console for schema management as well as configuration, administration,
loading, and monitoring of the Oracle Business Analytics Warehouse”. DAC is a
new age GUI avatar of what used to be done using multiple shell scripts/ Perl
scripts to load, maintain and administer the Datawarehouse, it can only do it
better and smarter. Historically the load, recovery and execution order was
built using scripting languages such as Unix shell scripts, Perl etc and these
scripts were executed using some kind of job scheduler (for example cron still
used to be the number one favorite job scheduler of administrators).
DAC consists of the
following three components:
·
DAC
Server- Executes the instructions from the DAC Client. The DAC Server
manages data warehouse processes, including loading of the ETL, recovery of the
ETL tasks, restarting ETL tasks in case of a failure and scheduling execution
plans. It can dynamically adjust its actions based on information in the DAC
repository. DAC provides various options to refresh the Oracle Business
Analytics Warehouse including daily, weekly, monthly or any other similar
schedules.
·
DAC
Client- A command and control interface for the data warehouse to allow for
schema management, and configuration, administration, and monitoring of data
warehouse processes. It also enables you to design subject areas and build
execution plans.
·
DAC
repository- Stores the metadata (semantics of the Oracle Business Analytics
Warehouse) that represents the data warehouse processes.
3.2.2 Informatica
This is one of the industry’s leading ETL platforms that perform
the extract, transform, and load (ETL) operations for the Datawarehouse.
Informatica consists of
the following components
·
Informatica
Services
The
main administrative unit of PowerCenter is the domain. The domain contains
nodes and application services that you manage in the PowerCenter
Administration Console. When you install PowerCenter on a single machine, you
create a domain with one node. All application services run on the node. When
you install PowerCenter on multiple machines, you create a domain with multiple
nodes. Install PowerCenter on one machine to create the domain and a node. Then
install PowerCenter on other machines and add those machines as gateway or
worker nodes in the domain. You can run the Integration Service and Repository
Service on separate nodes. You manage each domain through a separate
Administration Console. The PowerCenter installation process creates a service
named Informatica Services. Informatica Services runs as a service on Windows
and as a daemon on UNIX. When you start Informatica Services, Informatica
Services starts the Service Manager, which manages all domain operations.
The following table describes the components installed with
PowerCenter:
Component
|
Description
|
Informatica Services
|
This is the first service to start in the Informatica
list of services, only after this service is started that
an administrator can log into the thin client
Informatica admin console. Service manager is
primarily responsible for handling all domain
related operations include all administration,
Configuration and licensing activities.
|
Repository Service
|
Informatica repository contains all the metadata for
Informatica, repository service manages and
monitors all the connections to Informatica
repository
|
Integration Service
|
Informatica primary unit of code is called a
mapping and each mapping requires an integration
service to execute its ETL logic, So integration
services are take care of all the ETL executions to
The PowerCenter targets.
|
Metadata Manager Service
|
Informatica Metadata manager application manages
the metadata manager warehouse and metadata
manager service is the application service which
Executes the metadata manager application.
|
Reporting Service
|
Informatica can generate reports on the source
system data and other runtime logs, reporting service is the
application service that uses data
analyzer application to create and run such reports
|
Web Services Hub
|
Informatica workflows can be exposed as web
services and web services allow applications to
access these workflows in a cloud architecture
|
Java Runtime Environment
|
The java runtime required by the Service Manager
and some PowerCenter components.
|
DataDirect ODBC Drivers
|
ODBC drivers used by the Integration Service and the PowerCenter
Client
|
Informatica
client utilities
The PowerCenter Client installation includes desktop client
installations i.e. the PowerCenter and Metadata Manager Client tools. The
following table describes the primary client components installed with the
PowerCenter Client:
Component
|
Description
|
PowerCenter Client
|
The PowerCenter Client installation includes the following tools:
- Designer
- Repository Manager
- Workflow Manager
- Workflow Monitor
- Data Stencil
- Custom Metadata Configurator
|
DataDirect ODBC Drivers
|
ODBC drivers for use with the PowerCenter Client.
|
3.2.3 Pre-built Informatica content
The pre build Informatica content includes ETL repository objects, such as mappings, sessions, and workflows, and is contained in the Informatica Repository file (Oracle_BI_DW_Base.rep). The following Screen shows various Adaptors available in Informatica.
The Informatica ETL content is organized as folders which in
the OBIA world are termed as Adaptors, so for each source system and version
there will be an adaptor folder. This adaptor folder will basically contain all
the ETL components i.e all the mappings, sessions, and workflows which extract
transform and load data from a particular source for a specific version will be
grouped together under that adaptor folder. The adaptors are organized at two
levels:
The top most logical organization is at the kind of ETL which
is being supported by that adaptor, the prefix in the folder name identifies
this component, these prefixes and their description are as follows:
Prefix
|
Description
|
SDE
|
Source dependant extracts, these extracts are the etl components
which loads data directly from the source system to the staging tables.
|
SIL
|
Source Independent loads, these extracts are the etl components which
load data from the staging tables to the warehouse tables
|
PLP
|
Post Load process, most of
these etl components load aggregates, support updates and deletes.
|
UA
|
Universal Adaptors
|
The following table lists out the various adaptors and their
descriptions:
Adaptor
|
Description
|
JDE EnterpriseOne 8.11SP1 - 8.12
|
This adaptor contains ETL components such as workflows, session and
mappings for JD Edwards Enterprise version 8.11 SP1 and Version 8.12.
|
JDE EnterpriseOne 9.0
|
This adaptor contains ETL components such as workflows, session and
mappings for JD Edwards Enterprise version 9.0.
|
JDE World 9.2
|
This adaptor contains ETL components such as workflows, session and
mappings for JD Edwards World 9.2.
|
Oracle 11.5.10
|
This adaptor contains ETL components such as workflows, session and
mappings for Oracle ERP or Oracle Apps (ebusiness suite) version 11.5.10.
|
Oracle R12
|
This adaptor contains ETL components such as workflows, session and
mappings for Oracle ERP or Oracle Apps (ebusiness suite) version R12.
|
Oracle R12.1.1
|
This adaptor contains ETL components such as workflows, session and
mappings for Oracle ERP or Oracle Apps (ebusiness suite) version R12.1.1.
|
PeopleSoft 8.9
|
This adaptor contains ETL components such as workflows, session and
mappings for PeopleSoft version 8.9.
|
Siebel 7.8
|
This adaptor contains ETL components such as workflows, session and
mappings for Seibel Version 7.8.
|
Siebel 7.8 Vertical
|
This adaptor contains ETL components such as workflows, session and
mappings for industry specific Seibel Version 7.8.
|
Siebel 8.0
|
This adaptor contains ETL components such as workflows, session and
mappings for Seibel Version 8.0.
|
Siebel 8.0 Vertical
|
This adaptor contains ETL components such as workflows, session and
mappings for industry specific Seibel Version 8.0.
|
Siebel 8.1.1
|
This adaptor contains ETL components such as workflows, session and
mappings for Seibel Version 8.1.1.
|
Siebel 8.1.1 Vertical
|
This adaptor contains ETL components such as workflows, session and
mappings for industry specific Seibel Version 8.1.1
|
Universal
|
This adaptor contains ETL components such as workflows, session and
mappings for universal applications (homegrown applications, excel, XML
Sources etc).
|
3.2.4 Pre-built metadata content
All the pre-built metadata content for oracle BI Application is
stored in a metadata layer called OBIEE repository (in the Oracle BI world
aliased as rpd as the extension of these files is a .rpd), The Oracle BI
Repository stores the metadata information and each repository is capable of
storing many business models. The OBIEE repository consists of the following
three layers:
·
Physical Layer
This layer defines the objects and
relationships that the Oracle BI Server needs to write native queries against
each physical data source. This layer is created by importing tables, cubes,
and flat files from various data sources. OBIEE supports heterogeneous data
sources, so an OBIEE repository is capable of Integrating data from various
systems together for example in the OBIEE repository users can integrate SQL
server, DB2, Oracle, Informix, xls, xml and various other formats together.
For Oracle BI Application this
simple points to the BI Analytics warehouse
·
Business Layer
This layer defines the business or
logical model of the data and specifies the mapping between the business model
and the physical schemas. This layer determines the analytic behavior seen by
users, and defines the superset of objects and relationships available to
users. It also hides the Complexity of the source data models. Each column in
the business model maps to one or more columns in the Physical layer. At run
time, the Oracle BI Server evaluates Logical SQL requests against the business
model, and then uses the mappings to determine the best set of physical tables,
files, and cubes for generating the necessary physical queries. The mappings
often contain calculations and transformations, and might combine multiple physical
tables
For Oracle BI Application this layer
represents the collection of all the stars defined in section 4.
·
Presentation Layer
This layer provides a way to present customized, secure,
role-based views of a business model to users. It adds a level of abstraction
over the Business Model and Mapping layer and provides the view of the data
seen by users building requests in Presentation Services and other clients.
For Oracle BI Applications, The metadata content is contained
in the Oracle BI Applications repository file.
The following figure shows the Oracle BI Analytics Rpd and its
various layers

3.2.6 Pre-Built Reporting Content
The PRE-BUILT Reporting content is stored in OBIEE objects called catalogs, The Oracle BI actually stored objects, such as analyses, dashboards, and KPIs, that any user create using Oracle BI EE. Users have their own personal folder (My Folders), where they can store the objects that they create. The objects in a personal folder can be accessed only by the user who created and saved the content into that folder. Users can add sub-folders to their personal folders to organize their content in the way that is the most logical to them3.2.7 Oracle Business Analytics Warehouse
Oracle Analytics Warehouse is the pre-built data warehouse that
holds data extracted, transformed, and loaded from the transactional database.
Naming Convention
The Oracle Business Analytics Warehouse tables use a three-part
naming convention: PREFIX_NAME_SUFFIX
The following tables
details out this naming convention
Part
|
Meaning
|
Table Type
|
Prefix
|
Shows Oracle Business
Analytics-specific data warehouse
application tables.
|
W_ = Warehouse
|
Name
|
Unique table name.
|
All tables
|
Suffix
|
Indicates the table type.
|
_A = Aggregate
_D = Dimension
_DEL = Delete
_DH = Dimension Hierarchy
_DHL = Dimension Helper
_DHLS = Staging for Dimension Helper
_DHS = Staging for Dimension Hierarchy
_DS = Staging for Dimension
_F = Fact
_FS = Staging for Fact
_G, _GS = Internal
_H = Helper
_HS = Staging for Helper
_MD = Mini Dimension
_PE = Primary Extract
_PS = Persisted Staging
_RH = Row Flattened Hierarchy
_TL = Translation Staging (supports
multi-language support)
_TMP = Pre-staging or post-staging temporary
table
_UD = Unbounded Dimension
_WS = Staging for Usage Accelerator
|
Table Types Used in the
Oracle Business Analytics Warehouse
In this section we will cover up the various types of tables
inside the oracle Business Analytic Warehouse. Following are the key table
types and their details:
·
Aggregate
Tables
One of the main uses of a data warehouse is to sum up fact data
with respect to a given dimension, for example, by date or by sales region.
Performing this summation on-demand is resource-intensive, and slows down
response time. The Oracle Business Analytics Warehouse precalculates some of
these sums and stores the information in aggregate tables. In the Oracle
Business Analytics Warehouse, the aggregate tables have been suffixed with _A.
·
Dimension
Class Tables
A class table is a single physical table that can store
multiple logical entities that have similar business attributes. Various
logical dimensions are separated by a separator column, such as, type or
category. W_XACT_TYPE_D is an example of a dimension class table. Different
transaction types, such as, sales order types, sales invoice types, purchase
order types, and so on, can be housed in the same physical table. You can add
additional transaction types to an existing physical table and so reduce the
effort of designing and maintaining new physical tables.
·
Dimension
Tables
The unique numeric key (ROW_WID) for each dimension table is
generated during the load process. This key is used to join each dimension
table with its corresponding fact table or tables. It is also used to join the
dimension with any associated hierarchy table or extension table. The ROW_WID
columns in the Oracle Business Analytics Warehouse tables are numeric. In every
dimension table, the ROW_WID value of zero is reserved for Unspecified. If one
or more dimensions for a given record in a fact table is unspecified, the
corresponding key fields in that record are set to zero.
·
Dimension
Tables With Business Role-Based Flags
This approach is used when the underlying table is the same but
participates in analysis in various roles. As an example, an employee could
participate in a Human Resources business process as an employee, in the sales
process as a sales representative, in the receivables process as a collector,
and in the purchase process as a buyer. However, the employee is still the
same. For such logical entities, flags have been provided in the corresponding
physical table (for example, W_EMPLOYEE_D) to describe the record's
participation in business as different roles While configuring the presentation
layer, the same physical table can be used as a specific logical entity by
flag-based filters. For example, if a particular star schema requires Buyer as
a dimension, the Employee table can be used with a filter where the Buyer flag
is set to Y.
·
Fact
Tables
Each fact table contains one or more numeric foreign key
columns to link it to various dimension tables.
·
Helper
Tables (Bridge Tables)
Helper tables are used by the Oracle Business Analytics
Warehouse to solve complex problems that cannot be resolved by simple dimensional
schemas. In a typical dimensional
schema, fact records join to dimension records with a many-to-one relationship.
To support a many-to-many relationship between fact and dimension records, a
helper table is inserted between the fact and dimension tables.
·
Hierarchy
Tables
Hierarchy information related to a dimension table is stored in
a separate table, with one record for each record in the corresponding
dimension table. This information allows users to drill up and down through the
hierarchy in reports. There are two type
of hierarchies i.e fixed level hierarchies and parent child hierarchies as
parent child hierarchies are complex to implement Oracle BI Application uses
the the hierarchy bridge table approach to flatten hierarchies.
·
Staging
Tables
Staging tables are used primarily to
stage incremental data from the transactional database. When the ETL process
runs, staging tables are truncated before they are populated with change
capture data. During the initial full ETL load, these staging tables hold the
entire source data set for a defined period of history, but they hold only a
much smaller volume during subsequent refresh ETL runs. This staging data (list
of values translations, computations, currency conversions) is transformed and
loaded to the dimension and fact staging tables. These tables are typically
tagged as <TableName>_DS or <TableName>_FS. The staging tables for
the Usage Accelerator are tagged as WS_<TableName>.
The staging table structure is
independent of source data structures and resembles the structure of data
warehouse tables. This resemblance allows staging tables to also be used as
interface tables between the transactional database sources and data warehouse
target tables.
Column
Naming Convention
The Oracle Business Analytics Warehouse uses a standard prefix
and suffix to indicate fields that
Must contain specific values. The following table elaborates
more on the naming convention inside the Oracle Business Analytics Warehouse
Type
|
Name
|
Description
|
Table Type
|
Prefix
|
W_
|
Used to store Oracle BI Applications standard or
standardized values. For example, W_%_CODE
(Warehouse Conformed Domain) and W_TYPE,
W_INSERT_DT (Date records inserted into
Warehouse)
|
A
_D
_F
|
Suffix
|
_CODE
|
Code field.
|
_D, _DS, _FS, _G, _GS
|
_DT
|
Date field.
|
_D, _DS, _FS, _G, _DHL,
_DHLS
|
|
_ID
|
Correspond to the _WID columns of the
Corresponding _F table.
|
_FS, _DS
|
|
_FLG
|
Indicator or Flag.
|
_D, _DHL, _DS, _FS, _F, _G,
_DHLS
|
|
_WID
|
Identifier generated by Oracle Business Intelligence
linking dimension and fact tables, except for ROW_
WID.
|
_F, _A, _DHL
|
|
_NAME
|
A multi-language support column that holds the
name associated with an attribute in all languages
Supported by the data warehouse.
|
_TL
|
|
_DESCR
|
A multi-language support column that holds the
description associated with an attribute in all
languages supported by the data warehouse
|
_TL
|
System Columns
Oracle Business Analytics Warehouse tables contain system
fields. These system fields are populated automatically and should not be
modified by the user. The following table lists the system columns used in data
warehouse dimension tables.
Name
|
Description
|
ROW_WID
|
Surrogate key to identify a record uniquely
|
CREATED_BY_WID
|
Foreign key to the
W_USER_D dimension that specifies the user who created the record in the
source system.
|
CHANGED_BY_WID
|
Foreign key to the
W_USER_D dimension that specifies the user who last modified the record in
the source system.
|
CREATED_ON_DT
|
The date and time when
the record was initially created in the source system.
|
CHANGED_ON_DT
|
The date and time when
the record was last modified in the source system.
|
DELETE_FLG
|
This flag indicates the deletion status of the record in the source
system. A value of Y indicates the record is deleted from the source system
and logically deleted from the data warehouse. A value of N indicates that
the record is active.
|
W_INSERT_DT
|
Stores the date on which the record was inserted in the data
warehouse table.
|
W_UPDATE_DT
|
Stores the date on which the record was last updated in the
Datawarehouse table.
|
DATASOURCE_NUM_ID Unique
|
Identifier of the source system from which data was extracted. In
order to be able to trace the data back to its source, it is recommended that
you define separate unique source IDs for each of your different source
instances.
|
ETL_PROC_WID
|
System field. This column is the unique identifier for the specific
ETL process used to create or update this data.
|
INTEGRATION_ID
|
Unique identifier of a dimension or fact entity in its source system.
In case of composite keys, the value in this column can consist of
concatenated parts.
|
TENANT_ID
|
Unique identifier for a tenant in a multi-tenant environment. This
column is typically be used in an Application Service Provider (ASP)/Software
as a Service (SaaS) model
|
3.3 Oracle Business Intelligence Enterprise Edition
Oracle Business Intelligence
Enterprise Edition (OBIEE) the end users access framework to the Oracle
Business Applications. The end products such as analysis and Dashboards are
created using OBIEE Answers and Dashboard manager respectively. Oracle defines
OBIEE as follows:
“Oracle Business Intelligence
Enterprise Edition (OBIEE) is a comprehensive set of enterprise business
intelligence tools and infrastructure, including a scalable and efficient query
and analysis server, an ad-hoc query and analysis tool, interactive dashboards,
proactive intelligence and alerts, and an enterprise reporting engine. The
components of Oracle BI EE share a common service-oriented architecture, data
access services, analytic and calculation infrastructure, metadata management
services, semantic business model, security model and user preferences, and
administration tools. Oracle BI EE provides scalability and performance with
data-source specific optimized request generation, optimized data access,
advanced calculation, intelligent caching services, and clustering.”
3.3.1 OBIEE Logical Architecture
The highest unit of organization for an OBIEE
11g system is called an Oracle BI Domain. An Oracle BI Domain also called a WebLogic
Domain consists of Java, and
non-Java components, with the Java components being organized into a single unit. The
following figure shows the Oracle BI domain for an enterprise installation (Picture from owners Product manual, will be
replaced upon completion of graphics)

WebLogic
domain, for an Enterprise Install, initially consists of a single
Administration Server and Managed Server (described in the later sections),
with the Administration Server containing the WebLogic Administration Console,
Oracle Enterprise Manager and Java MBeans applications, and the Managed Server
containing all the OBIEE Java components such as BI Publisher, the Action
Service, the BI Middleware application and the BI Office application.
BI Server, BI Presentation Server and other
“traditional” OBIEE server components (collectively referred as System
Components), alongside the Java components are referred as an Instance, with
each instance being managed by its own installation of OPMN, or Oracle Process
Manager and Notification Server. When we
scale-out an OBIEE system over several hosts, there can be several instances,
once for each host. Collectively, these instances together are
termed as a Farm, in the Enterprise Manager console shown as (Farm_BI_Foundation)
and Farm is something which we manage using Oracle Enterprise Manager Console. The following figure shows the
Farm_BI_Foundation.

The
following sections provide further details on each component of an Oracle BI
Instance
3.3.2 Administration Server
The Administration Server contains the
administrative components that enable administration of a single or multimode
(that is, distributed) BI domain, the sub components available inside the
administration server depends on the type of installation, these installation
scenarios are as follows
Ø Enterprise Install
Fusion
Middleware Control: An
administrative user interface that is used to manage the BI domain.
WebLogic
Server Administration Console: An
administrative user interface that provides advanced management for WebLogic,
JEE components, and security.
JMX
MBeans: These are Java components that provide programmatic access for
managing a BI domain.
Ø Simple Install
The Administration Server also
contains the components that comprise the Managed Server in an Enterprise
Install type, such as Action Services and Oracle BI Publisher.
3.3.3 Managed Server
Managed server is a
JEE container which has components such as adds (MS-office plug-in), Action
services and web services. Deployed as a JEE container that runs in a dedicated
Java virtual machine that provides the run-time environment for the Java-based
services and applications within the system. These services and applications
include BI Publisher and Oracle Real-Time Decisions. An Oracle BI domain
contains one or more Managed Servers that are distributed across one or more
host computers.
3.3.4 Node Manager
A node can represent a machine, a disk
or a disk partition on a RAC environment. The function of a node manager is to
administer and refresh the hardware components in the obiee framework. Node
manager Provides process management services for the Administration Server and
Managed Server processes.
3.3.5 Oracle Process Manager and Notification Server (OPMN) Tool
Oracle Process Manager and Notification
Server (OPMN) is a process management tool that manages the Oracle Business
Intelligence system components. OPMN supports both local and distributed
process management, automatic process recycling, and the communication of
process state (up, down, starting, and stopping). OPMN detects process
unavailability and automatically restarts processes).
Following are some of the key
functions for OPMN:
·
Provide a command-line interface for advanced
users to control Oracle Fusion Middleware components.
·
Automatic restart of processes when they become
unresponsive or terminate unexpectedly.
·
An
integrated way to manage Oracle Fusion Middleware components
3.3.6 Java Components
Following are the key Java Components
available inside the OBIEE framework:
·
Administrative
Components: Oracle WebLogic Server Administration Console, Fusion
Middleware Control, and JMX MBeans for managing all configuration and run-time
settings for Oracle Business Intelligence.
·
Oracle BI
Publisher: This component provides an enterprise reporting solution for
authoring, managing, and delivering all types of highly formatted documents to
employees, customers, and suppliers.
·
Oracle BI
for Microsoft Office: This component provides the integration between
Oracle Business Intelligence and Microsoft Office products.
·
Oracle BI
Action Services: This component
provides the dedicated Web services that are required by the Action Framework
and that enable an administrator to manually configure which Web service
directories can be browsed by users when they create actions.
·
Oracle
Real-Time Decisions (Oracle RTD):
This component provides enterprise analytics software solutions that
enable companies to make better decisions in real time at key, high-value
points in operational business processes.
·
Oracle BI
Security Services: This component
provides dedicated Web services that enable the integration of the Oracle BI
Server with the Oracle Fusion Middleware security platform.
·
Oracle BI
SOA Services: This component
provides dedicated Web services for objects in the Oracle BI Presentation
Catalog, to invoke analyses, agents, and conditions. These services make it
easy to invoke Oracle Business Intelligence functionality from Business Process
Execution Language (BPEL) processes.
·
Oracle BI
Presentation Services Plug-in: This
component is a JEE application that routes HTTP and SOAP requests to Oracle BI
Presentation Services
3.3.7 Other Domain Contents
Includes all the necessary software,
metadata, configuration files, RPD files, Oracle BI Presentation Catalog, and
connection and database configuration information that are required to run an
Oracle Business Intelligence system
4) Universal Business Adapters
Universal
Business Adapters are used for sources with no pre-packaged business
adapter, i.e. primarily for non standard sources such as excel, csv,.dat
and in some cases legacy systems (mainframes, Cobol etc), these
adaptors when used adeptly can even load data for unstructured sources
(web catalogs, web logs, application server logs etc) and integrate them
into the mainstream analytic warehouse. This is actually how we can
define universal adaptors in the best possible way but does this
definition explain it all? I hope not let’s try a real time example
You
are an ever expanding organization, your sources for the OBIA analytics
warehouse were well defined and standardized for example you had 3
standard source systems Ebiz, JD Edwards and PeopleSoft supplying all
your products details. Now just based on your long term strategy you
occupied another organization "xyz corporation", this organization is a
startup company which still relies on excel to load product details,
your concern now is how do you integrate the product details from xyz
organization into the mainstream analytic warehouse. Universal
adaptors can resolve this problem for you; the following process
explains how you can leverage universal adaptors to resolve this
scenario in BIApps
1) Open the folder SDE_Universal_Adaptor by doing a right click and selecting open
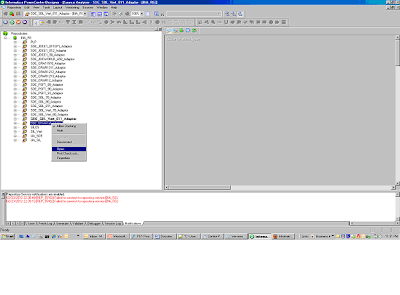
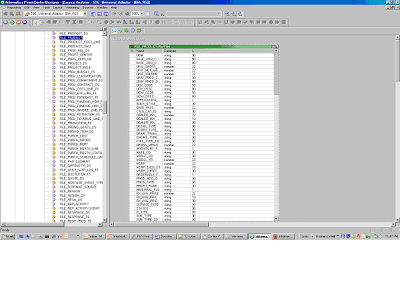
2) Open the mapping SDE_Universal_ProductDimension

3) Map the file to the equivalent Source definition, there are two ways to do this either:
3.1) you can customize the output file from Xyz Corporation to be similar to the source definition in this mapping.
3.2)
or you can change the source definition itself (change the source
definition to match the output file from Xyz Corporation) but this will
also require changing this mapping flow too.
4) Define a task for this mapping in the DAC execution plan:
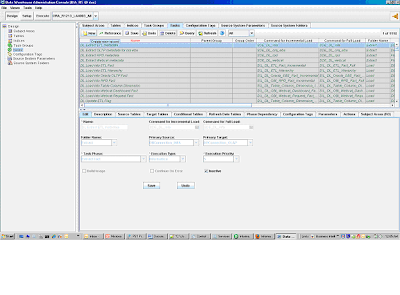
5) There
is no pre-defined task defined for custom jobs inside DAC, so this
custom Universal Adaptor Mapping needs to be defined as a task and
included into the DAC process flow. Note of caution here
· DAC
determines order of execution of mappings based on some predefined
algorithms so one needs to be careful on the ordering of this custom
task.
· Mappings get associated to DAC tasks through names and folders also DAC needs some predefined parameters to execute an Informatica mapping
· Trying this mapping as a micro etl might distort the consistency of the Datawarehouse.



***********************Multi Source Loads With OBIA***********************
8.1) Multi Source Loads With OBIA
Multi Source loads refer to the situation where we load data from two of more source instances of similar or dissimilar types. Some common examples include:
Multi Source loads refer to the situation where we load data from two of more source instances of similar or dissimilar types. Some common examples include:
Ø
Loading data from two similar type instances
separated geographically for example EBS 11i in US and EBS 12i in Japan
Ø
Multi
source load from dissimilar instance such as an instance of Siebel 7.8 in one location
and of Oracle EBS 12i in another location.
Anyways, there are two key things to be noted in the case of
a multi source load and this has primarily to do with the locking mechanism if
they are seeking same targets and the truncate table, drop index and analyze
table sequence. These details are as follows:
Multi-Source Order of Execution
The order in which DAC loads data from the different sources
that are participating in
the ETL process is determined by the priority of the
physical data source connection (set in the Physical Data Sources tab of the
Setup view). The Priority property ensures that tasks attempting to write to
the same target table will not be in conflict.
Note this property is primarily responsible if
the sources are of the same types for example EBS11i and EBS 12i then one of
them can be given a priority 1 and the next physical data source a different
priority
Delay
As shown in the following Figure , the Delay
property is located in the Parameters subtab in the Execution Plans tab of the
Execute view. You set this property to specify how many minutes an extract of a
data source will be delayed after the first extract of a multiple source
extract process started.
Folder Level Priorities
As shown in the following Figure, you need to set the folder
level priority in the Task Physical Folders dialog box, which you by selecting
Tools, then Seed Data, and then Task Physical Folders.

I know that the first question which must be immediately bothering
you is if we can set the priority at the data source connection level itself
then why do we need the priority at the physical folder level, well indeed
there is a very specific business case for that. Imagine that you have a Seibel
7.8 and an EBS 12 implementation in US plus an EBS 12i implementation in Japan.
Then what should be the best mechanism to set the priorities that these loads
run in a mixed mode (combination of parallel and serial mode) and the
performance is optimum. What you might have to do is first set the priorities
at the data source level for the EBS sources for Japan and US, as it’s the same
physical folder there is no way that we can set different priorities at the physical
folder level, next you need to set the priority for Seibel at the physical
folder level.
7.3 Full Load vs Incremental Loads
One of the key concepts in OBIA is the mechanism thru which incremental
and full loads have been of implemented. The details are as follows:
Ø
In Informatica almost for every mapping there
will be 2 types of workflows i.e. there will one workflow for the full load and
another for incremental load.
Ø
In most
of the cases these workflows will be calling the same set of routines (ETL
mappings) except that the Incremental workflows will have Incremental sessions
that have a SQL override with a condition such as EFFECTIVE_DATE
>=$$LAST_REFRESH_DATE. Due to this condition these workflows will only
extract the changed data set (Delta).
Ø
Another
key thing to note here is the there is a separate set of mappings for
identifying records that have been physically deleted from the source system,
these mappings are The primary extract (*_Primary) and delete mappings
(*_IdentifyDelete and *_Softdelete) mappings. These mappings use $$LAST_ARCHIVE_DATE
mechanism to update the warehouse with source related deletions.
Ø
When you
run an execution plan, the type of task or workflow which will be executed will
be decided based on the value of the refresh date for the primary source or
primary target table, If the refresh date is null DAC will automatically choose
the task with full load workflow and if there is a value available for the
refresh date DAC will execute the respective incremental workflow.
Note: The tasks with _full denote
that it is used while running the full load and the other task with no _full
will indicate that it is used for incremental load.
If you want to view this In DAC, you can see these both
workflows in Design > Tasks and select any one task and in the lower pane go
to Edit tab. In Edit tab, there will be a Command for Incremental load and
Command for full load and you will find the both the workflow names within
these fields. The taks with _full will be in Command for full load and the
other will be in Command for incremental load.
Hi ,
ReplyDeleteI wanted to know if you can seperate the Admin console on a seperate host and managed server on a seperate host .
Hi
DeleteSorry about the delay in reply was completly submerged in winding up my book. Now the answer for the above is yes, you can have the RPD admin client on any machine you want. you only need to provide the odbc connection and you will be all set to work as if the admin client is on the server.
Drop me a note on my gmail account arun.bi.architect@gmail.com if there are any further queries.
Regards
Arun Pandey